Confluence Q&A App on Shakudo with Langchain and ChatGPT
Chatbot interactions have been revolutionized with advancements in AI and NLP like OpenAI's GPT and LangChain. In this post, we'll explore how to use Shakudo to simplify and enhance the process of building a Q&A app for an Internal Knowledge base from conceptualization to deployment. We chose Confluence for this tutorial because it's an optimal platform for creating internal knowledge bases. Its intuitive interface supports efficient information management, and its advanced search capabilities ensure that you find what you need without unnecessary delays.
Want to skip to the code? It’s available on GitHub.
The problem:
ChatGPT's human-like capability to extract information from vast data has truly transformed the field of language models. But with a 4096-token context limit, extracting details from extensive text documents is still a challenge. There are multiple ways to get around this problem.
Option one involves generating text snippets and sequentially prompting the large language model (LLM), refining the answer step by step. Although this method covers the text effectively, it falls short when it comes to time and cost efficiency due to its resource-intensive nature.
Option two involves utilizing LLMs with larger context windows, such as the Claude model by Anthropic, offering a 100k-token window. However, it partially solves the problem as we need to ensure that the model can accurately and comprehensively extract from our extensive knowledge base.
Option three capitalizes on the power of embeddings and similarity search and is the one we chose for the tutorial. It maintains an embedding vector store for each text snippet, calculates question embeddings, and retrieves the nearest text snippets via a similarity search on embedding. The retrieved text snippets are used to query the LLM with by constructing a prompt to obtain an answer
Solution overview:
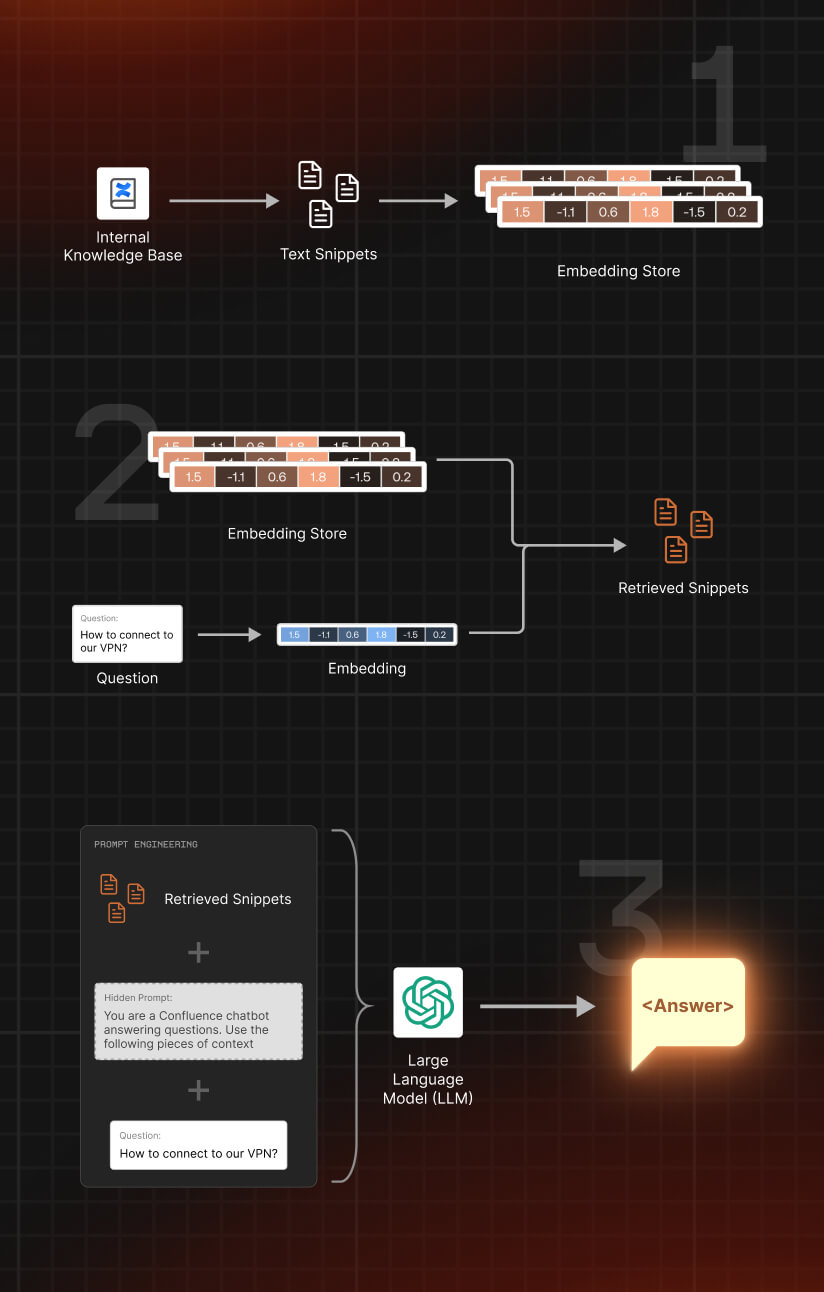
Our proposed architecture operates as a pipeline that efficiently retrieves information from a knowledge base (in this case, Confluence) in response to user queries. It includes four main steps:
- Step 1: Knowledge base processing
This step involves transforming information from a knowledge base into a more manageable format for subsequent stages. Information is segmented into smaller text snippets and vector representations (embeddings) of these snippets are generated for quick and easy comparison and retrieval. Here, we use Langchain's ConfluenceLoader with TextSplitter and TokenSplitter to efficiently split the documents into text snippets. Then, we create embeddings using OpenAI's ada-v2 model.
- Step 2: User query processing:
When a user submits a question, it is transformed into an embedding using the same process applied to the text snippets. Langchain's RetrievalQA, in conjunction with ChromaDB, then identifies the most relevant text snippets based on their embeddings.
- Step 3: Answer generation
Relevant text snippets, together with the user's question, are used to generate a prompt. This prompt is processed by our chosen LLM to generate an appropriate response to the user's query.
- Step 4: Streamlit service and Shakudo deployment
Finally, we package everything into a Streamlit application, expose the endpoint, and deploy it on a cluster using Shakudo. This step ensures a seamless transition from development to production quickly and reliably, as Shakudo automates DevOps tasks and lets developers use Langchain, Hugging Face pipelines, and LLM models effortlessly with pre-built images.
Setting up the environment
We use OpenAI's adav2 for text embeddings and OpenAI's gpt-3.5-turbo as our LLM. OpenAI offers a range of embedding models and LLMs. The ones that we have chosen balance efficiency and cost-effectiveness, but depending on your needs, other models might be more suitable.
ConfluenceQA initialize
This stage involves preparing the embedding model for text snippet processing and the LLM model for the final query response. Our go-to models are ada-v2 for embeddings and gpt-3.5-turbo for text generation, respectively. Learn more about embeddings from OpenAI Documentation.
embedding = OpenAIEmbeddings()
After that, let’s initialize the LLM model to be used for the final LLM call to query with prompt:
llm = ChatOpenAI(model_name=LLM_OPENAI_GPT35, temperature=0.)
The 'temperature' parameter in the LLM initialization impacts the randomness of the model's responses, with higher values producing more random responses and lower values producing more deterministic ones. Here, we've set it to 0, which makes the output entirely deterministic.
OpenAI key setup
To wrap up the environment setup, we specify the OpenAI API key, a prerequisite for LangChain's functionality. Make sure the API environment key is named OPENAI_API_KEY – it's a requirement for LangChain.
import os
os.environ["OPENAI_API_KEY"] ="sk-**"
For security, we store the key in a .env file, and ensure the key is correctly recognized by our application. Never print or share your keys as this can expose them to potential security threats.
With our environment set up, we are now ready to start building our Confluence Q&A application.
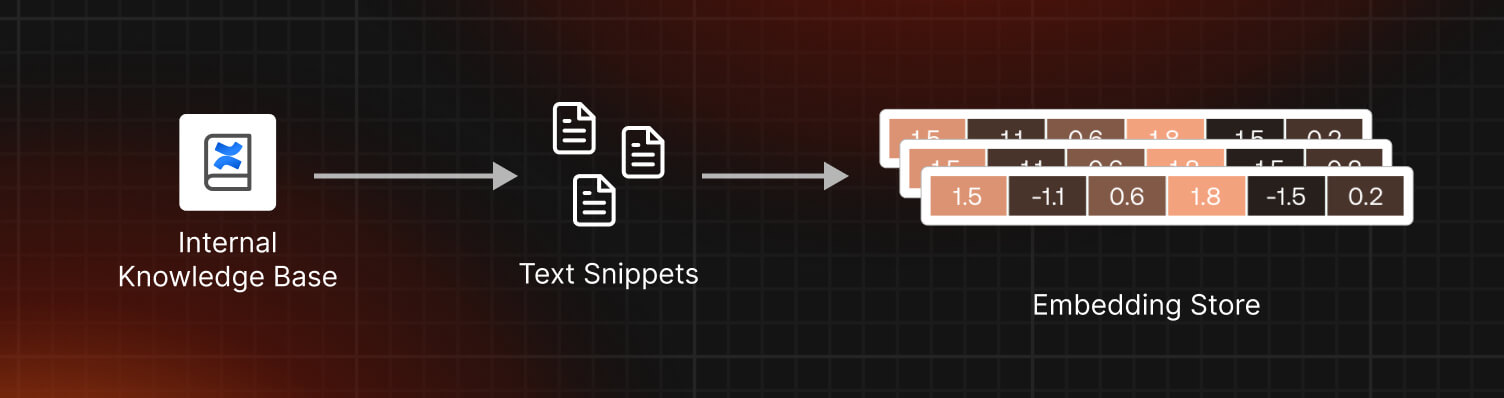
Step 1: Creating an Embedding Store from the knowledge base:
In this step, we will extract the documents from the Confluence knowledge base, transform these documents into text snippets, generate embeddings for these snippets, and store these embeddings in a Chroma store.
Extract the documents with ConfluenceLoader
ConfluenceLoader is a powerful tool that allows us to extract documents from a Confluence site using login credentials. It currently supports username/api_key and OAuth2 authentication methods. Be careful when handling these credentials, as they are sensitive information.
config = {"persist_directory":"./chroma_db/",
"confluence_url":"https://templates.atlassian.net/wiki/",
"username":None,
"api_key":None,
"space_key":"RD"
}
persist_directory = config.get("persist_directory",None)
confluence_url = config.get("confluence_url",None)
username = config.get("username",None)
api_key = config.get("api_key",None)
space_key = config.get("space_key",None)
## 1. Extract the documents
loader = ConfluenceLoader(
url=confluence_url,
username = username,
api_key= api_key
)
documents = loader.load(
space_key=space_key,
limit=100
)
Splitting Documents into Text Snippets:
Next, we split these documents into smaller, manageable text snippets. We employ CharacterTextSplitter and TokenTextSplitter from LangChain for this task.
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=10, encoding_name="cl100k_base") # This the encoding for text-embedding-ada-002
texts = text_splitter.split_documents(texts)
Generating Embeddings and Adding to Chroma Store:
Lastly, we generate embeddings for these text snippets and store them in a Chroma database. The Chroma class handles this with the help of an embedding function.
if persist_directory and os.path.exists(persist_directory):
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
else:
vectordb = Chroma.from_documents(documents=texts, embedding=embedding, persist_directory=persist_directory)
We have now successfully transformed our knowledge base into a store of embedded text snippets, ready for efficient querying in the subsequent stages of our pipeline.
For a dynamic confluence pages, the vector store creation process can be scheduled with the help of Shakudo jobs pipeline (Link Shakudo Jobs pipeline documentation here)
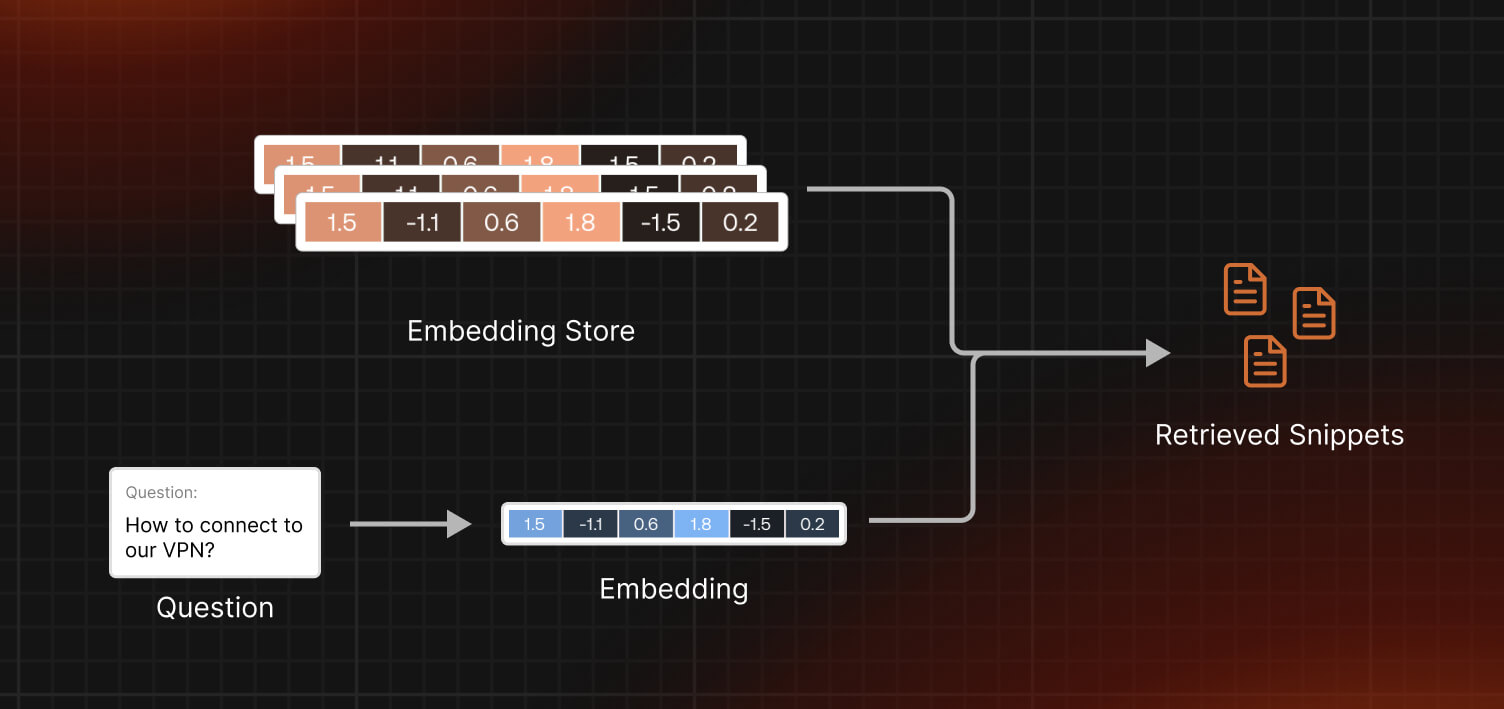
Step 2: Computing questions embeddings and finding relevant snippets
ChromaDB is an advanced indexing system that accelerates retrieval by finding and matching things that have the same meaning. This makes our process quicker and more accurate.
Next, we create "questions embeddings" to understand the meaning behind the questions. This is like converting the questions into a language that ChromaDB speaks fluently. Now, ChromaDB can pinpoint the most useful snippets of information. These snippets form the foundation of smart and detailed responses in our app.
These steps enhance the effectiveness of our RetrievalQA chain. This ensures that our app delivers fast, accurate, and useful answers to the questions received. In the next step, we will show you how it works along with prompt engineering.
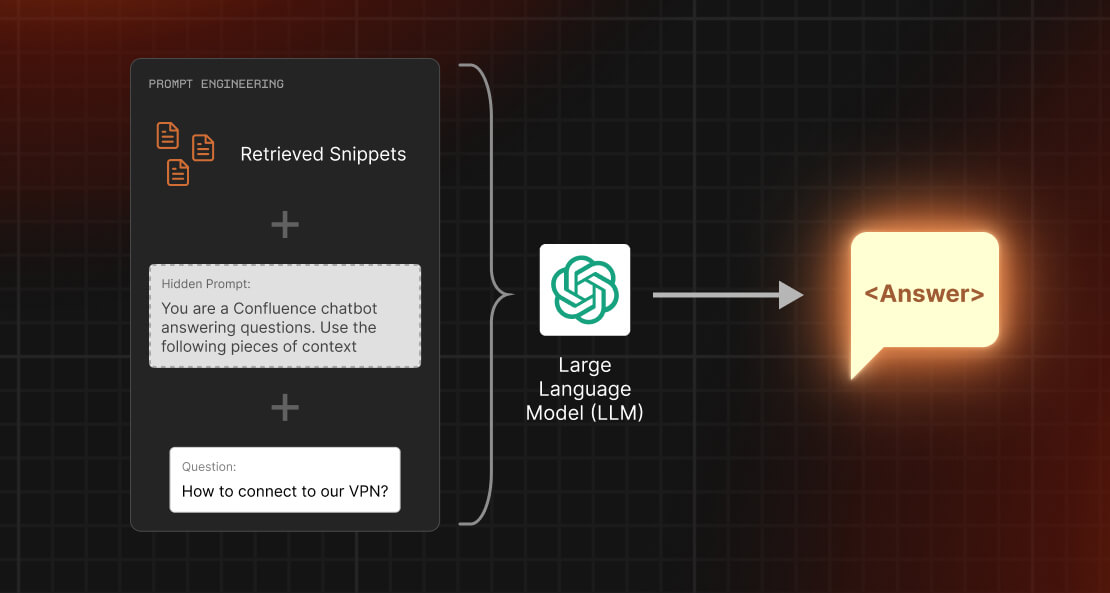
Step 3: Prompt engineering and LLM query
In this step, we construct a prompt for our LLM. A prompt is a message that sets the context and asks the question that we want the LLM to answer. To pass a custom prompt with context and question, you can define your own template as follows:
custom_prompt_template = """You are a Confluence chatbot answering questions. Use the following pieces of context to answer the question at the end. If you don't know the answer, say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Helpful Answer:"""
CUSTOMPROMPT = PromptTemplate(
template=custom_prompt_template, input_variables=["context", "question"]
)
## Inject custom prompt
qa.combine_documents_chain.llm_chain.prompt = CUSTOMPROMPT
retriever = vectordb.as_retriever(search_kwargs={"k":4}) #Top4-Snippets
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff",retriever=retriever)
question = "How to organize content in a space?"
answer = qa.run(question)
print(answer)
# Answer: To organize content in a space, you can create pages or blogs for different types of content. Pages can have child pages, which allows you to organize content into categories and subcategories. You can also use labels to categorize and identify content, and create a table of contents for your space using the Content Report Table Macro. Additionally, you can customize the sidebar to make it easier to navigate through your space and add a search box to find content within your space.
In the following class, ConfluenceQA, we package all the necessary steps that include initializing the models, embedding, and combining the retriever and answer generator into one organized module. This encapsulation improves code readability and reusability.
class ConfluenceQA:
def __init__(self,config:dict = {}):
self.config = config
self.embedding = None
self.vectordb = None
self.llm = None
self.qa = None
self.retriever = None
...
# You can see the full script on Github
Once the ConfluenceQA class is set up, you can initialize and run it as follows:
# Configuration for ConfluenceQA
config = {"persist_directory":"./chroma_db/",
"confluence_url":"https://templates.atlassian.net/wiki/",
"username":None,
"api_key":None,
"space_key":"RD"}
# Initialize ConfluenceQA
confluenceQA = ConfluenceQA(config=config)
confluenceQA.init_embeddings()
confluenceQA.init_models()
# Create Vector DB
confluenceQA.vector_db_confluence_docs()
# Set up Retrieval QA Chain
confluenceQA.retreival_qa_chain()
# Query the model
question = "How to organize content in a space?"
confluenceQA.answer_confluence(question)
Remember that the above approach is a structured way to access the Confluence knowledge base and get your desired information using a combination of embeddings, retrieval, and prompt engineering. However, the success of the approach would largely depend on the quality of the knowledge base and the prompt that is used to question the LLM.
Step 4: Streamlit app
Let’s wrap our solution in a Streamlit app and deploy it as a service. This will make it accessible either locally or on a cloud-based cluster.
Building a Streamlit App
To create an interactive web application around our ConfluenceQA class, we use Streamlit, a Python library that simplifies app creation. Below is the breakdown of the code:
We start by importing necessary modules and initializing our ConfluenceQA instance:
import streamlit as st
from confluence_qa import ConfluenceQA
st.set_page_config(
page_title='Q&A Bot for Confluence Page',
page_icon='⚡',
layout='wide',
initial_sidebar_state='auto',
)
st.session_state["config"] = {}
confluence_qa = None
We then define a sidebar form for user inputs:
with st.sidebar.form(key ='Form1'):
# Form fields and submit button go here
And finally, we provide a user interface for asking questions and getting answers:
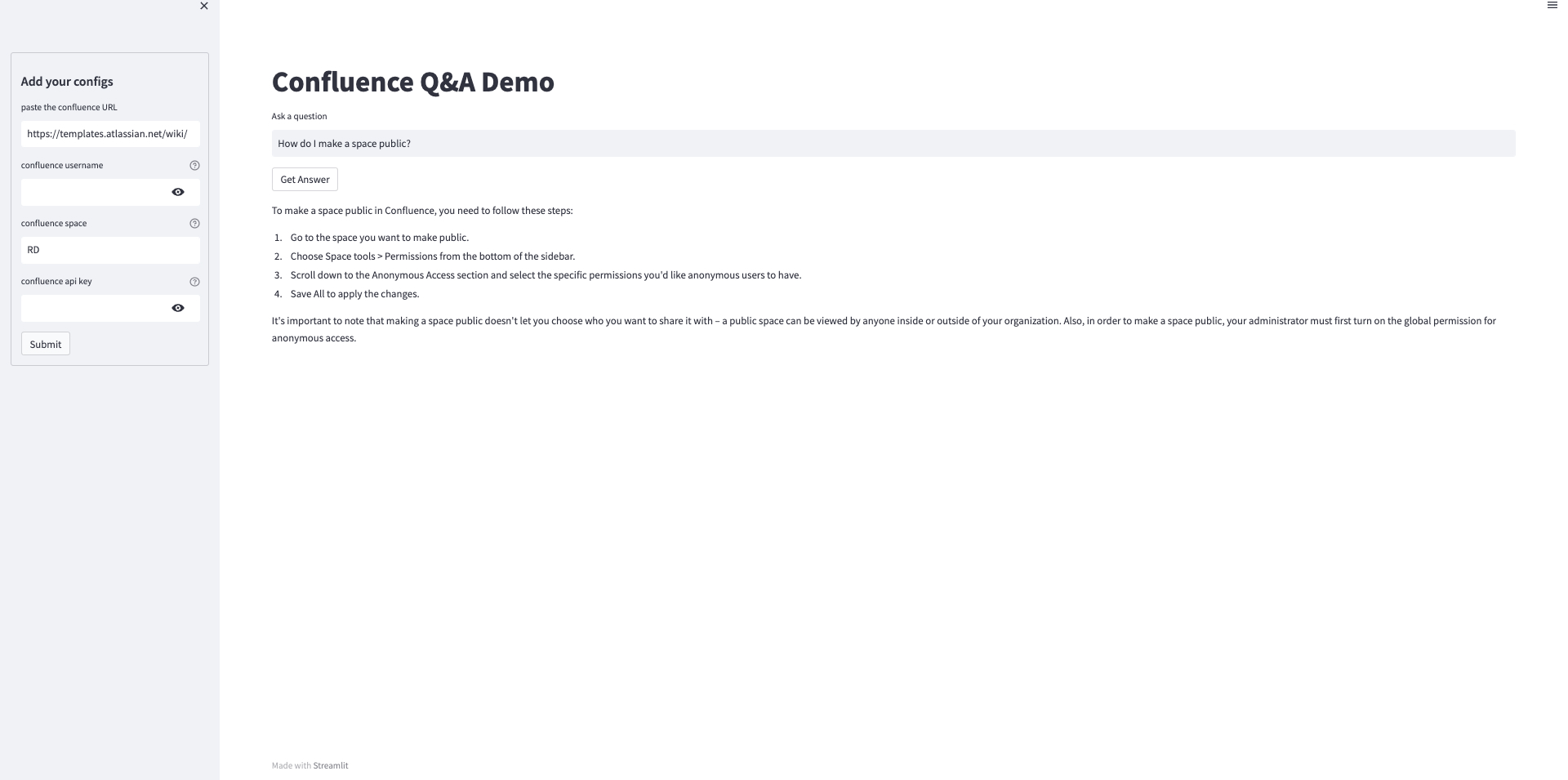
st.title("Confluence Q&A Demo")
question = st.text_input('Ask a question', "How do I make a space public?")
if st.button('Get Answer'):
# Code to generate and display the answer
This Streamlit app can be launched locally or on a cluster and allows us to interact with our Confluence Q&A system in a user-friendly manner.
Deploying with Shakudo
Finally our app is ready, and we can deploy it as a service on Shakudo. The platform makes the process of deployment easier, allowing you to quickly put your app online.
To deploy our app on Shakudo, we need two key files: pipeline.yaml, which describes our deployment pipeline, and run.sh, a bash script to set up and run our application. Here's what these files look like:
- ‘pipeline.yaml’:
pipeline:
name: "QA demo"
tasks:
- name: "QA app"
type: "bash script"
port: 8787
bash_script_path: "LLM/confluence_app/run.sh"
- ‘run.sh’:
PROJECT_DIR="$(cd -P "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
cd "$PROJECT_DIR"
pip install -r requirements.txt
export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
export STREAMLIT_RUNONSSAVE=True
streamlit run app.py --server.port 8787 --browser.serverAddress localhost
In this script:
- Set the project directory and navigate into it.
- Install the necessary Python libraries from the requirements.txt file.
- Set two environment variables to: PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION and STREAMLIT_RUNONSSAVE.
- Runthe Streamlit app on port 8787.
After you have these files ready, navigate to the service tab and click the '+' button to create a new service. Fill in the details in the service creation panel and click 'CREATE'. On the services dashboard, click on the ‘Endpoint URL’ button to access the application. Check out the Shakudo docs for a more detailed explanation.
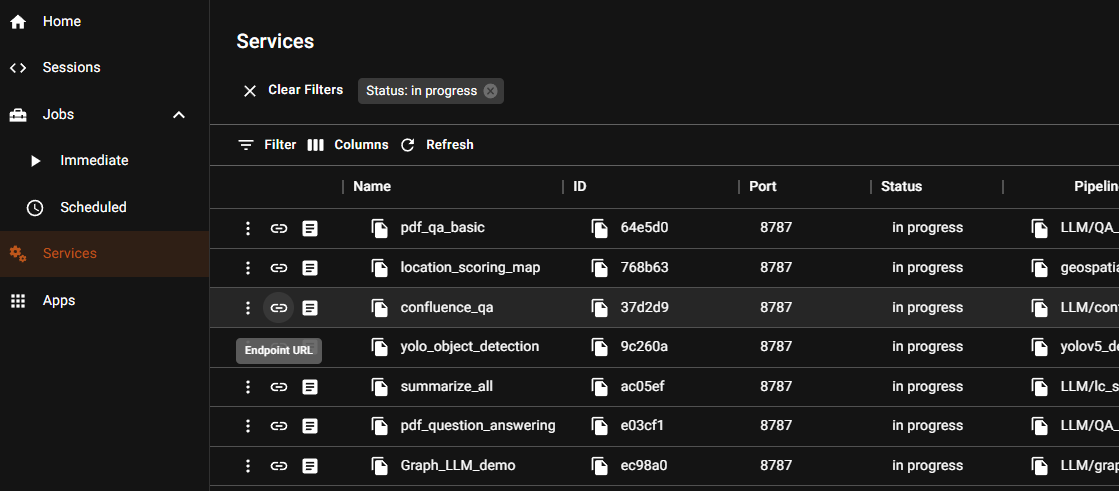
Now, your application is live! You can browse through the user interface to see how it works.
Adopting Shakudo into your workflow
Shakudo is designed to facilitate the entire lifecycle of data and AI applications. Automating all stages of the development process, including the stack integrations, deployment, and the ongoing management of data-driven applications.
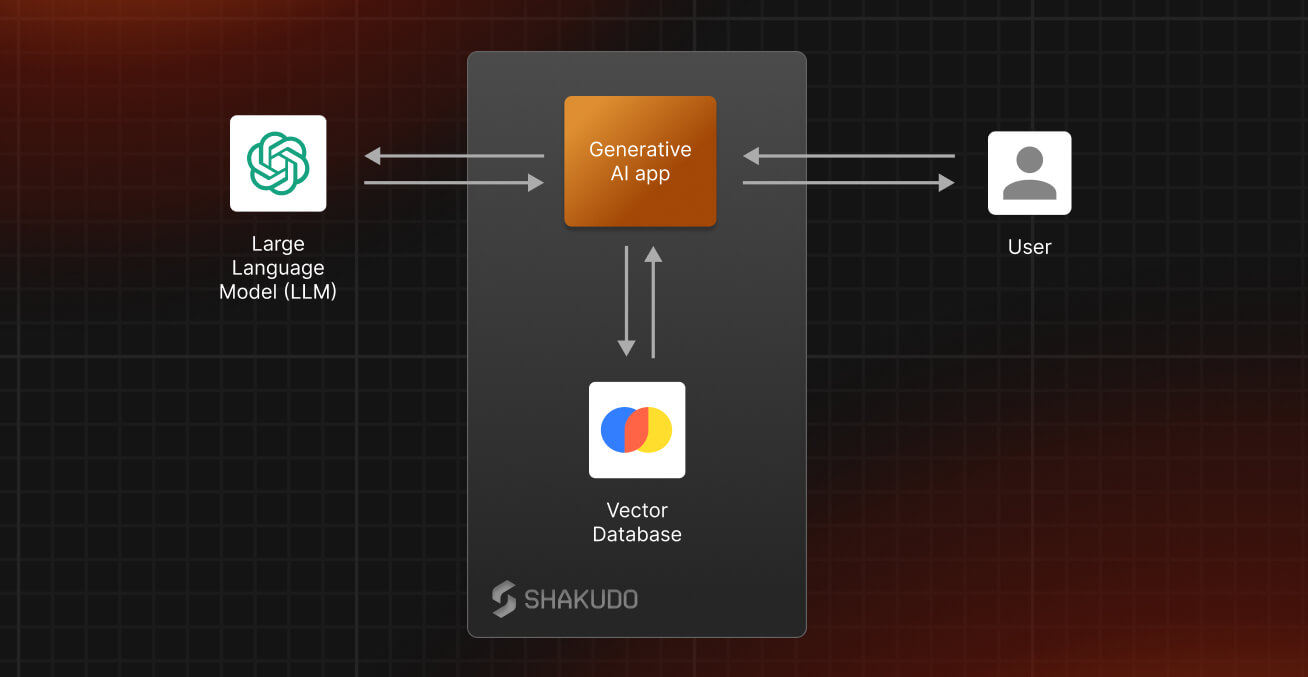
By using Shakudo, you’ll take advantage of:
- Integrated Environment: Shakudo is designed to provide compatibility across a diverse range of best-of-breed data tools. This unique feature facilitates experimentation and the creation of a data stack that's not only more reliable and performant but also cost-effective.
- Continuous Integration and Deployment (CI/CD): Shakudo automates the stages of application deployment with managed Kubernetes. This ensures rapid deployment and eliminates the complex task of self-managing a cluster, resulting in more reliable releases and data flows.
- Services Deployment and Pipelines Orchestration: With Shakudo you can deploy your app as a service that shows an endpoint, be it a dashboard, a website, or an API endpoint. It also facilitates the creation and orchestration of data pipelines, reducing setup time to only a few minutes.
Conclusion
This blog provides a comprehensive guide to developing a Confluence Q&A application utilizing the power of Shakudo, Langchain, and ChatGPT, aiming to resolve the challenge posed by ChatGPT's token limit when extracting information from extensive text documents. We used a new method leveraging embeddings and similarity search, ensuring a more efficient process of retrieving accurate information from a knowledge base.
Are you ready to start building more efficient data-driven applications? Check out our blog post on “How to Easily and Securely Integrate LLMs for Enterprise Data Initiatives”. Feel free to reach out to our team to check out how you can start using Shakudo to help your business. Thank you for reading and happy coding!
References:
- This code is adapted based on the work in LLM-WikipediaQA, where the author compares FastChat-T5, Flan-T5 with ChatGPT running a Q&A on Wikipedia Articles.
- Buster: Overview figure inspired from Buster’s demo. Buster is a QA bot that can be used to answer from any source of documentation.
- Claude model: 100K Context Window model from Anthropic AI